Background
As one of the most popular online news entities, The New York Times (NYT) attracts thousands of unique visitors each day to its website, nytimes.com. Users who visit the site can provide their thoughts and reactions to published content by posting comments.
The website receives around 9,000 submitted comments per day, over 60,000 unique contributors per month, and approximately two million comment recommendations (i.e., "likes") each month. There is a dedicated moderation staff committed to review each submission one-by-one and even hand-select the very best comments as "NYT Picks."
The Times embraces this personal, intimate approach to comment moderation based on the hypothesis that "readers of The Times would demand an elevated experience." Click here to learn more about the staff at the NYT who work on this.
Our Angle
We have examined the relationship between comment success (i.e., the number of recommendations it receives by other users and if it is selected as a NYT Pick) as well as other features about the comments themselves. Specifically, we have built a model that can predict the success of a given comment. We envision this model as a complementary tool that could be used by the moderators during their daily review of comments. For example, perhaps there is a comment they are unsure about; they could run our model to see the comment's predicted success.
This tool could also benefit the commenters themselves. Perhaps this model could help a commenter predict how their draft comment would perform once submitted. An effective prediction system could also be used in an automated comment recommender to help steer users toward higher quality content.
The Times cares about its comments, as is evident in a recent piece published where their top 14 commenters were identified and interviewed.

Comments, Comments, Comments
The NYT website receives nearly a quarter million comment submissions a month. After analyzing a set of 180,000 comments spanning 2 years, we were able to learn some interesting statistics about all these comments.
Most people only comment once
Assuming commenters do not use multiple accounts, the statistics indicate that most comments come from users who have never posted before. In other words, since the median of our dataset is 1, this implies the majority of users who post, only post once. The mean, however, is 4, which is due to a few outliers included in the overall calculation.
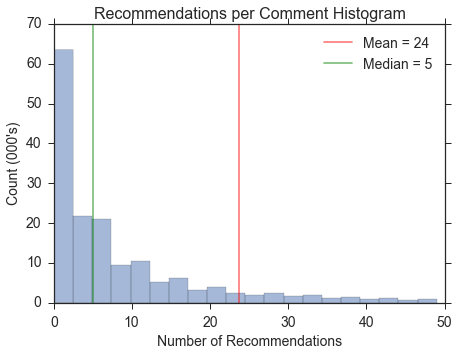
Majority of comments receive <5 recommendations
As it turns out, most comments receive fewer than five recommendations. However, there are examples of highly recommended comments (not shown). With a max of 3,064 recommendations, the mean is larger relative to the median.
It's hard to be a NYT Pick
Out of our 180,000 comments, we found less than 3% to be designated as Editor's Pick. Of those picks, we see that they get more recommendations that those that are not picks. Specifically, NYT Picks comments receive an average of 180 recommendations. A high correlation between recommendation count and NYT Pick would not be surprising, but it is an interesting statistic nonetheless.
The Data
Scraping
We obtained the comment data from The New York Times API. The API operates similarly to the Huffington Post API that was used earlier in the course.
Transformation
We transformed the recommendation count of all comments into two classes, 'high' and 'low', to make prediction easier. This meant that all comments with less than 16 recommendations were considered 'low' (the 75th percentile) and all above that were classified as 'high'.
Features
Bag of words
We use a binary bag of words feature that encodes which of the 200 most popular words appear in a comment.
Avg. word length
Longer, more sophisticated word usage may correlate with better comments.
Word count
The word count may be indicative of the quality of a comment.
Sentiment
We used sentiment analysis to extract a positive and negative sentiment score for every comment. We hypothesized that comment recommendations may depend on sentiment, as posts with a strong sentiment are likely to be more controversial than neutral posts.
Term specificity (tf-idf)
Intuitively, tf-idf measures how important a word is in a document compared with how important the word is to the corpus as a whole. Words that appear frequently in documents but appear rarely in the corpus receive high scores.
We investigated various relationships between the above features. For example, below is a scatter plot depicting the relationship between a comment's positive sentiment score and its term specificity (tf-idf) score. As shown, as comments become more positive and their terms more specific, they appear to receive more recommendations.
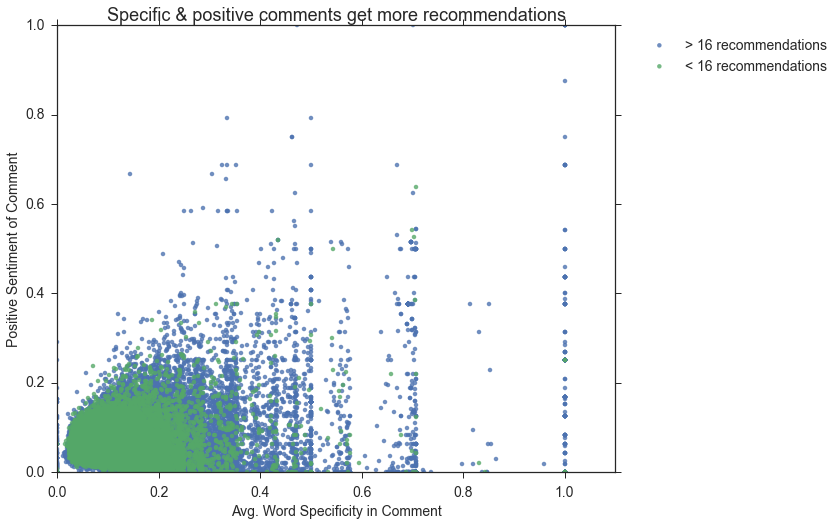
The Model
We tried several models (for example, linear regression and random forest regression) on the recommendation count data. But, when we found that these models performed poorly, we switched to binary classification of high recommendation and low recommendation posts at a cutoff value of the 75th percentile (16 recommendations). For this classification problem, we again tried multiple models, among which were linear SVC and the random forest classification. The random forest classifier performed moderately well, but the rest still performed quite poorly.
Results
Our random forest classifier performed okay, with a precision of 0.98, and a recall of 0.75. The accuracy, at 0.75, was unfortunately not higher than a baseline 'low' predictor.
Here's a summary of our results:
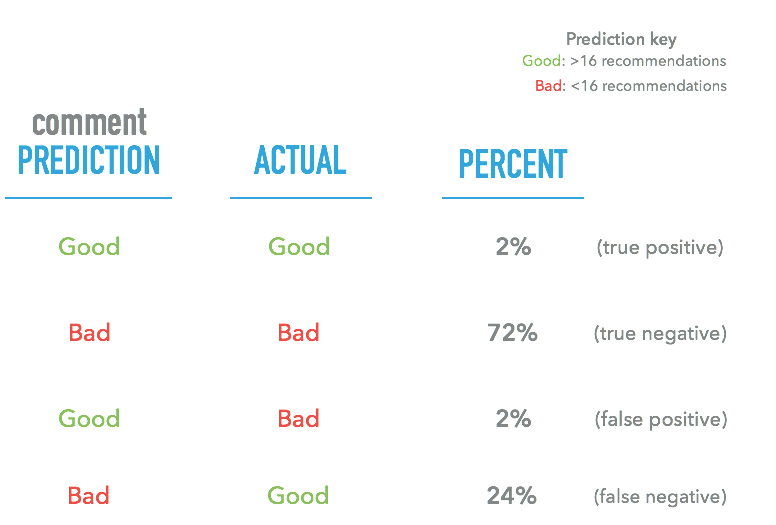
As you can see, we are dealing with a substantial amount of false negatives. This means it is hard for the model to mark actual good posts as good. Identifying bad comments, ones that have a low recommendation count, on the other hand, is easy.
Discussion
We had a great deal of trouble generating an even moderately useful prediction. There were two main reasons for this: (1) highly unbalanced data, and (2) the difficulty of natural language processing.
Unbalanced data: As we showed above, the majority of comments have very few recommendations, and only a small proportion of comments are designated as NYT Picks. This results in a dataset where predicting zero recommendations and NYT Picks is effective at minimizing error. It is, in general, hard to make any sort of good predictions when the data is this unbalanced. One straightforward, but time-consuming, approach to ameliorating this problem is to get more data. This would likely be the first step in a future analysis. 180,000 comments is only a small proportion of the total comments posted each year, and collecting more data would give us more popular comments on which to train our models.
NLP: NLP is a deep and complicated field, and since we did not have prior experience, we were able to perform only rudimentary feature selection. Given more time, we could research and implement more sophisticated feature selection techniques and engineer features that carry more information about the comments.
We could further improve our model by exploring how an article relates to its comments. As a simple example, positive sentiment sentiment comments on restaurant reviews might fare better than positive comments on highly politicized editorials. A model could derive more complex relationships. With a larger sample of comments and article data, we could use a deep learning approach to derive insights from the complicated relationships between articles and comments, and between comments and other comments. Building a model that incorporates article text and metadata could be very powerful; unfortunately, it would also require much more data scraping and much more sophisticated methods, both of which are time-prohibitive.